Every tester now has a roomful of AI assistants on call. The harder question is no longer whether to use them — it is knowing which one to reach for, and when.
When the tools are new, the instinct is to pick a favourite and route everything through it. That feels efficient. In practice it quietly caps your results: you overspend time and tokens on trivial work, and you under-serve the decisions that actually deserve depth.
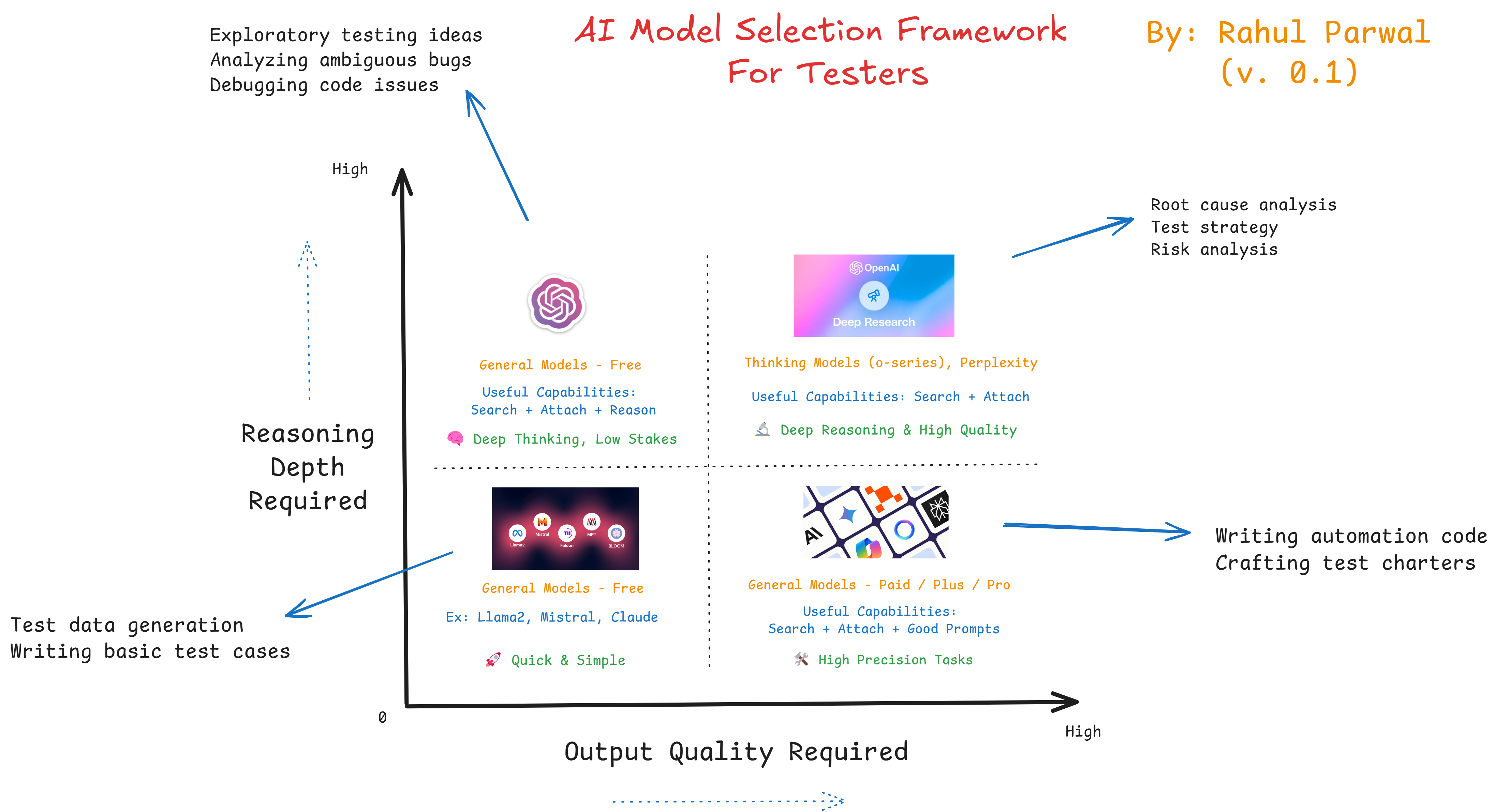
AI can accelerate a task, surface an insight, or open a line of thinking you had not considered. What it cannot do is decide what good looks like for the work in front of you. That judgement stays with the tester. A simple framework makes it repeatable — and it rests on just two questions you can ask of any task.
Choosing an AI model is not about finding the smartest tool. It is about matching the tool to the weight of the task.
The two dimensions that matter
- Reasoning depth
How much genuine thinking does the task demand?- Generating throwaway test data asks almost nothing of a model.
- Untangling an intermittent, environment-specific bug asks a great deal.
- Output quality
How finished must the result be?- An ideation dump can be rough and still valuable.
- A risk assessment that leadership will act on must be precise, structured, and defensible.
Plot any task against these two axes and it lands in one of four zones. Each zone has a natural class of model — and a natural way to work with it.
The four quadrants
1. Routine, high-volume work (low reasoning, low quality)
These are the chores of testing — necessary, repetitive, and rarely the best use of your attention. Hand them off and reclaim the time for work that needs a human.
Examples:
- Generating test data.
- Drafting first-pass test cases.
- Producing boilerplate and scaffolding.
Reach for: fast, lightweight, low-cost models — the kind optimised for speed and volume rather than depth. Free tiers are usually more than enough.
How to work with it: let the model do the groundwork, treat the output as a starting point, and sanity-check the basics before you rely on it.
2. Thinking partner (high reasoning, low quality)
Here you are not after a finished artefact. You want a model that will think alongside you — challenge an assumption, widen the search space, and help you reason toward a hypothesis.
Examples:
- Exploring test ideas and angles.
- Debugging an unfamiliar failure.
- Making sense of a vague or incomplete bug report.
Reach for: reasoning-focused “thinking” models that can work through a problem step by step. Raw capability matters more than polish here.
How to work with it: ask it to reason explicitly, treat its ideas as raw material rather than answers, and refine in your own voice afterwards.
3. Polished output, simple logic (low reasoning, high quality)
Some work is not intellectually demanding but must arrive clean, structured, and ready to use. Precision and presentation carry more weight than raw insight.
Examples:
- Writing automation code.
- Building detailed checklists.
- Drafting test charters.
Reach for: capable general-purpose models tuned for accurate, well-formatted output — typically the stronger paid tiers.
How to work with it: give clear formatting and structure instructions up front, review the result, and treat it as a strong draft rather than the final word.
4. High-stakes, high-fidelity (high reasoning, high quality)
This is the demanding corner of the map: work that requires both real analytical depth and a polished, defensible result. The cost of a shallow or sloppy answer here is high.
Examples:
- Conducting risk analysis.
- Performing root-cause investigations.
- Designing a comprehensive test strategy.
Reach for: frontier models — the most capable reasoning systems available — used deliberately and fed with rich context.
How to work with it: supply ample context, ask for the reasoning behind its conclusions, and build your prompts in layers rather than expecting one shot to land.
Orchestrating models, not choosing one
The most interesting work rarely sits neatly in a single quadrant. A real testing problem tends to travel across the map as it matures — and the strongest results come from moving the work between models as it does.
A typical workflow:
- Open with a fast, general model to generate options and get unstuck.
- Hand the promising threads to a reasoning model to pressure-test the hypothesis.
- Close with a precision model to document the findings cleanly.
Why it works: it spends time and tokens where they earn their keep, matches each phase to the right capability, and keeps quality high without over-engineering the simple steps.
The real skill
Do you route every task through one model out of habit? What would change if you matched the model to the weight of the work?
Map your next handful of testing tasks onto these two axes before you reach for a tool. The exercise takes a minute, and it quietly changes what you reach for.
The point was never to crown a single best model. It is to match the tool to the task — fast models for routine work, frontier models for the decisions that carry weight — so your effort lands where it matters. Let the right model carry the load while you stay on the part only a tester can do: knowing what good looks like, and judging whether the work meets it.
Also, check out the AI usage for testers: Quadrants model — Rahul’s Testing Titbits, a companion piece to this framework.